苹果的深度学习框架:BNNS 和 MPSCNN 的对比
05 Mar 2018
原文链接:http://machinethink.net/blog/apple-deep-learning-bnns-versus-metal-cnn/
原文作者:MATTHIJS HOLLEMANS
苹果的深度学习框架:BNNS 和 MPSCNN 的对比
从 iOS 10 开始,苹果在 iOS 平台上引入了两个深度学习的框架:BNNS 和 MPSCNN。
-
BNNS:全称为香蕉(bananas,译者注:此处开玩笑),Basic Neural Network Subroutines,是 Accelerate 框架的一部分。这个框架能够充分利用 CPU 的快速矢量指令,并提供一系列的数学函数。
-
MPSCNN 是 Metal Performance Shaders 的一部分。Metal Performance Shaders 是一个经过优化过的计算内核框架,并且可以运行在 GPU (而不是 CPU)上。
所以,作为 iOS 开发者,现在有了两个用来做深度学习的 APIs,并且它们看起来很相似。
应该选择哪个呢?
在这篇文章中,我们将针对 BNNS 和 MPSCNN 进行对比来显示出这两者的差异。而且我们会对这两个 API 进行速度测试,来看下谁更快一些。
为什么要首先使用 BNNS 或 MPSCNN ?
我们首先讨论这两个框架的作用。
目前 BNNS 和 MPSCNN 在卷积神经网络领域中用于执行推断。
与类似的 TensorFlow(使用此方案可以通过构建一个计算图,从头开始建立你的神经网络)相比,BNNS 和 MPSCNN 提供更高级的 API,不需要担心你的数学。
这也有一个缺点:BNNS 和 MPSCNN 的功能远远少于其他框架,如 TensorFlow。它们更容易上手,但同时限制了所能做的深度学习的种类。
苹果的深度学习框架只是为了一个目的:通过网络层级尽可能快地传递数据。
一切都与层级有关
你可以将神经网络想象为数据流经的管道。管道中的不同阶段便是网络层级。这些层级以不同的方式转换你的数据。同时深度学习,我们可以使用多达 10 层甚至 100 层的神经网络。
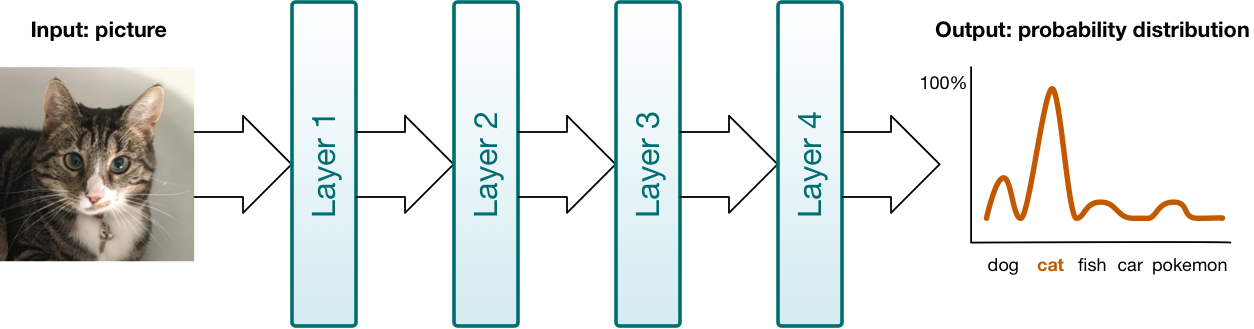
层级有不同的种类。BNNS 和 MPSCNN 提供的有:卷积层(convolutional layer)、池化层(pooling layer)、全连接层(Fully Connected Layer)和规范化层(normalization layer)。
在 BNNS 和 MPSCNN 中,层级是主要的建构单元。你可以创建层级对象,将数据放入层级中,然后再从层级中读出结果。顺便说一句,BNNS 称它们为“过滤器”,而不是层级:数据以一种形式进入过滤器并以另一种形式从过滤器出来。
为了说明层级作为建构单元的思想,下面描述了数据如何通过一个简单的神经网络在 BNNS 中流动:
// 为中间结果和最终结果分配内存。
var tempBuffer1: [Float] = . . .
var tempBuffer2: [Float] = . . .
var results: [Float] = . . .
// 对输入的数据(比如说一张图片)应用第一层级。
BNNSFilterApply(convLayer, inputData, &tempBuffer1)
// 对第一层级的输出应用第二层级。
BNNSFilterApply(poolLayer, tempBuffer1, &tempBuffer2)
// 应用第三和最后的层级。结果通常是概率分布。
BNNSFilterApply(fcLayer, tempBuffer2, &results)
要使用 BNNS 和 MPSCNN 构建神经网络,只需要设置层级并向它们发送数据。框架负责处理层级内发生的事情,但你需要做的是连接层级。
不幸的是,这可能有点无聊。例如,通过加载一个提前训练好的 caffemodel 文件来获取一个完整配置的“神经网络”是行不通的。你必须手写代码,仔细地创建层级并进行配置来复制出网络的设计。这样就很容易犯错。
BNNS 和 MPSCNN 不做训练
在你使用神经网络之前,你必须先训练它。训练需要大量的数据和耐心——至少几个小时,甚至几天或几周,取决于你可以投入多少计算能力。你肯定不想在手机上进行训练(这可能会使手机着火)。
一旦网络训练完成,便可以用来进行预测。这被称为“推理”。虽然培训需要一些专用的重型计算机,但在现代的手机上进行推理是完全可能的。
这正是 BNNS 和 MPSCNN 设计的目的。
仅限卷积网络
但是这两个 API 都有限制。目前,BNNS 和 MPSCNN 仅支持一种深度学习:卷积神经网络(CNN)。CNN 的主要应用场景是机器视觉任务。例如,你可以使用 CNN 来描述给定照片中的对象。
虽然 CNN 很牛逼,但在 BNNS 或 MPSCNN 中无法支持其他深度学习架构(例如递归神经网络)。
然而,已经提供的建构单元(卷积层,池化层和完全连接层)高效并且为构建更复杂的神经网络提供了良好的基础,即便你必须手工编写一些代码来填补 API 中的空白。
- 备注:Metal Performance Shaders 框架还附带有用于在 GPU 上进行快速矩阵乘法的计算内核。同时,Accelerate 框架包含用于在 CPU 上执行相同操作的 BLAS 库。所以,即使 BNNS 或 MPSCNN 不包含你所需的深层学习架构的所有层级类型,你也可以借助这些矩阵例程来推出自己的层级类型。而且,如果有必要的话,你可以用 Metal Shading Language 编写你自己的 GPU 代码。
不同之处
假如它们的功能一致,那为何 Apple 要给我们两个 API?
很简单:BNNS 运行在 CPU 上,MPSCNN 运行在 GPU 上。有时使用 CPU 速度更快,有时使用 GPU 更快。
- “等一下…难道 GPU 不是高度并行的计算怪物么?难道我们不应该一直在 GPU 上运行我们的深层神经网络吗?!”
并没有。对于培训,你一定希望通过 GPU 来进行大规模并行计算(即使只是一个许多 GPU 的集群)但推论时,使用枯燥的旧的 2 或 4 核 CPU 可能会更快。
下面我将详细讨论的速度差异,但首先让我们来看看这两个 API 是有哪些不同。
- 备注:Metal Performance Shaders 框架仅适用于 iOS 和 tvOS,不适用于 Mac。BNNS 也适用于 macOS 10.12 及更高版本。如果你想要保证 iOS 和 MacOS 之间的深度学习代码的可移植性,BNNS 是你唯一的选择(或使用第三方框架)。
它是 Swifty 的么?
BNNS 实际上是一个基于 C 的 API。如果你使用 Objective-C 是可以的,但 Swift 使用它有点麻烦。相反,MPSCNN 更兼容 Swift。
不过,你必须接受这些 API 比所谓的 UIKit 更低级的事实。Swift 并没有将所有的东西都抽象成简单的类型。你经常需要使用 Swift 的 UnsafeRawPointer 指针来处理原始字节。
Swift 也没有一个原生的 16 位浮点类型,但是 BNNS 和 MPSCNN 在使用这样的半精度浮点数时才是最高效的。你将不得不使用 Accelerate 框架在常规类型和半精度浮点数之间进行转换。
从理论上讲,当使用 MPSCNN 时,你不必自己编写任何 GPU 代码,但实际上我发现某些预处理步骤——如从每个图像像素中减去平均 RGB 值,使用 Metal Shading Language(基于 C++ 实现) 中的定制的计算内核是最容易实现的。
所以,即使你在 Swift 中使用这两个框架,也要准备好用这两个 API 来进行一些底层级别的 Hacking 行为。
激活函数
随着数据在神经网络中从一层流向下一层,数据在每层都会以某种方式被转换。层级应用了激活函数,来作为此转换的一部分。没有这些激活函数,神经网络将无法学习非常有趣的事情。
激活函数有很多选择,BNNS 和 MPSCNN 都支持最常用的功能:
- 修正线性单元(ReLU)和带泄漏修改线性单元(Leaky ReLU)
- 逻辑函数(logistic sigmoid)
- 双曲正切函数(tanh)和 扩展双曲正切函数(scaled tanh)
- 绝对值
- 恒等函数(the identity function),它传递数据而不改变数据
- 线性(只在 MPSCNN 上)
你会认为这与 API 一样简单,但是奇怪的是,与 MPSCNN 相比,BNNS 有一个不同的定义这些激活函数的方式。
例如,BNNS 定义了两种类型,BNNSActivationFunctionRectifiedLinear 和 BNNSActivationFunctionLeakyRectifiedLinear,但在 MPSCNN 中,只有一种 MPSCNNNeuronReLU 类型,使用 alpha 参数来标记是否为带泄漏的修正线性单元(Leaky ReLU)。同样的还有双曲正切函数(tanh)和 扩展双曲正切函数(scaled tanh)。
可以肯定地说,MPSCNN 采用比 BNNS 更灵活和可定制的方法。整个 API 层面都是如此。
例如:MPSCNN 允许您通过继承 MPSCNNNeuron 并编写一些 GPU 代码来创建自己的激活函数。使用 BNNS 就无法实现,因为没有用于定制的激活函数的 API;只提供了枚举。如果你想要的激活函数不在列表中,那么使用 BNNS 就会掉进大坑。
-
17年2月10号更新:以上内容有点误导,所以我应该澄清下。由于 BNNS 在 CPU 上运行,你可以简单地获取层级的输出并根据你的喜好进行修改。如果你需要一种特殊的激活函数,你可以在 Swift 中自己实现(最好使用 Accelerate 框架)并在进入下一层之前将其应用于上一层的输出。所以 BNNS 在这方面的能力不亚于 Metal。
-
17年6月29日更新:关于
MPSCNNNeuron子类的澄清:如果你这样做,实际上并不能使用MPSCNNConvolution的子类。这是因为 MPS 在 GPU 内核中执行激活函数时使用了一个技巧,但这只适用于 Apple 自己的 MPSCNNNeuron 子类,不适用于你自己创建的任何子类。
事实上,在 MPSCNN 中,一切都是 MPSCNNKernel 的一个子类。这意味着你可以单独使用一个激活函数,如 MPSCNNNeuronLinear,就像它是一个单独的层级一样。在预处理步骤中,这对以常量进行缩放数据是很有用的。(顺便说一句,BNNS 没有类似于“线性”的激活函数。)
- 备注:在我看来,感觉就像 BNNS 和 MPSCNN 是由 Apple 内部不同的团体创建的。它们有非常相似的功能,但它们的 API 之间有一些奇怪的差异。我不在 Apple 公司工作,所以我不知道这些差异存在的原因。也许是出于技术或性能的原因。但是你应该知道 BNNS 和 MPSCNN 不是“热插拔”的。如果你想要知道在 CPU 或 GPU 上进行推理时哪种方法最快,你将不得不实现两次深度学习网络。
层级类型
我之前提到深层神经网络是由不同类型的层级组成的:
- 卷积(Convolutional)
- 池化(Pooling),最大值和平均值
- 完全连接(Fully-connected)
BNNS 和 MPSCNN 都实现了这三种层级类型,但是每种 API 的实现方式都有细微差别。
例如,BNNS 可以在池化层中使用激活函数,但是 MPSCNN 不行。但是,在 MPSCNN 中,你可以将激活函数添加到池化层后面作为单独的一层,所以最终这两个 API 能实现相同的功能,但是它们实现的路径不同。
在 MPSCNN 中,完全连接层被视为卷积的一个特例,而在 BNNS 中,它被实现为矩阵向量乘法。实践中并不会有差别,但是这表明这两个框架采取了不同的方法来解决同样的问题。
我觉得对于开发者来说,MPSCNN 使用起来更方便。
当对图像使用卷积时,除非添加“填充”像素,否则输出图像会缩小一些。使用 MPSCNN,就不必担心这一点:你只需告诉它,希望输入和输出图像有多大。使用 BNNS 你就必须自己计算填充量。像这样的细节让 MPSCNN 成为更易用的 API。
除了基础层级,MPSCNN 还提供以下层级:
- 规范化层()
- Softmax
- 对数 Softmax
- 使用激活函数作为层级
这些额外的层级类型无法在 BNNS 中找到。
对于规范化层来说,这可能不是什么大问题,因为我觉得它们并不常见,但 softmax 是大多数卷积网络在某些时候需要做的事情(通常在最后)。
softmax 函数将神经网络的输出转化为概率分布:“我 95% 肯定这张照片是一只猫,但只有 5% 确定它是一只神奇宝贝。”
在 BNNS 中没有提供 softmax 是有点奇怪的。在 Accelerate 框架中使用 vDSP 函数来写代码实现并不难,但是也不是很方便。
学习参数
训练神经网络时,训练过程会调整一组数字来表示网络正在学习什么。这些数字被称为学习参数。
学习参数由所谓的权重和偏差值组成,这些值只是一些浮点数。当你向神经网络发送数据时,各层级实际上将你的数据乘以这些权重,添加偏差值,然后再应用激活函数。
创建层级时,需要为每个层级指定权重和偏差值。这两个 API 只需要一个原始指针指向浮点值的缓冲区。需要由你来确保这些数字以正确的方式组织。如果这里操作错误,神经网络将会输出垃圾数据。
你可能猜到了:BNNS 和 MPSCNN 为权重使用不同的内存分配。😅
对于 MPSCNN 权重数组看起来像这样:
weights[ outputChannel ][ kernelY ][ kernelX ][ inputChannel ]
但是对于 BNNS 来说,顺序是不同的:
weights[ outputChannel ][ inputChannel ][ kernelY ][ kernelX ]
我认为 MPSCNN 将输入通道放在最后的原因是,这样可以很好地映射到存储数据的 MTLTextures 中的 RGBA 像素。但是对于 BNNS 所使用的 CPU 矢量指令,将输入通道视为单独的内存块会更高效。
这种差异对于开发者来说不是一个大问题,但是当你导入训练好的模型时你需要知道权重的内存分配。
备注:你可能需要编写一个转换脚本来导出培训工具中的数据,例如 TensorFlow 或 Caffe,并将其转换为 BNNS 或 MPSCNN 预期的格式。这两个 API 都不能读取这些工具所保存的模型,它们只接受原始的浮点值的缓冲数据。
MPSCNN 总是复制权重和偏差值,并将它们作为 16 位浮点内部存储。由于你必须将它们作为单精度浮点数提供,因此这有效地将你的学习参数的精度减半。
BNNS 在这里比较开放一些:它可以让你选择你想要存储学习参数的格式,也可以让你选择不复制。
将权重加载到网络中仅仅在创建网络时的 App 启动时起到重要作用。但是,如果你有大量的权重,你仍然需要认真对待。我的 VGGNet implementation 不能在 iPhone 6 上工作,因为 App 试图一次性将所有权重加载到 MPSCNN 时导致内存不足。(可以先创建大的层级,然后是再创建较小的层级。)
输入数据
一旦你创建了所有的层级对象,你终于可以开始使用神经网络进行推断啦!
正如你所看到的,BNNS 或 MPSCNN 都没有真正的“神经网络”的概念,他们只能看到每个层级。你需要逐个将数据放入这些层级中的每一层。
作为神经网络的用户,你关心的数据是进入第一层(例如图片)的输入和从最后一层出来的输出(图片是猫的概率)。其他的一切,在各层之间传递的数据,只是暂时的中间结果,并不是很有趣。
那么你需要输入什么格式的数据?
MPSCNN 要求将所有数据放置在一个特殊的 MPSImage 对象内,这个对象实际上是 2D 纹理的集合。如果你正在使用图片,这会非常有意义 - 但是如果你的数据不是图片,则需要将其转换为 Metal 纹理。这会消耗 CPU 的性能。(你可以使用 Accelerate 框架来解决这个问题。)
备注:iOS 设备使用统一的内存模型,这意味着 CPU 和 GPU 访问相同的 RAM 芯片。与桌面计算机或服务器上的情况不同,你不需要将数据复制到 GPU。所以至少你的 iOS App 不会有这些性能消耗。
另一方面,BNNS 只需要一个指向浮点值缓冲区的指针。不需要将数据加载到特定对象中。所以这似乎比使用纹理更快…是么?
这样有一个重要的限制:在 BNNS 中,不同“通道”中的输入不能交错。
如果你的输入是图片,那么它有三个通道:一个用于红色像素,一个用于绿色像素,另一个用于蓝色像素。问题是像 PNG 或 JPEG 这样的图像文件会作为交错的 RGBA 值被加载到内存中。BNNS 并不会接受这种情况。
目前没有办法告诉 BNNS 使用红色像素值作为通道 0,绿色像素值作为通道 1,蓝色值作为通道 2,并跳过 alpha 通道。相反,你将不得不重新排列像素数据,以便输入缓冲区的首先包含所有 R 值,然后是所有 G 值,然后是所有 B 值。
我们若采取这种预处理,就会占用宝贵的计算时间,这太不幸了。其次,也许这些限制允许 BNNS 在其层级如何执行其的计算方面做一定的优化,从而使整个事情是个净增益。但这谁也不知道。
在任何情况下,如果您使用 BNNS 处理图像(CNNs主要的用途)那么你可能需要对输入数据进行一些调整以获得正确的格式。
还有数据类型的问题。
BNNS 和 MPSCNN 都允许你将输入数据指定为浮点值(16 位和 32 位)或整数(8、16 或 32 位)。你想将浮点数据作为网络的输入,你可能无法选择输入数据的格式。
通常,当你加载 PNG 或 JPEG 图像,或者从手机相机中取出静止图像时,会得到一个纹理,该纹理使用无符号的 8 位整数作为像素的 RGBA 值。使用 MPSCNN 这是没有问题的:纹理会自动转换为浮点值。
用 BNNS 你可以指定 Int8 作为图像的数据类型,但是我这么做真的不行。公平的说,我也没有花很多时间——既然我已经不得不重新整理输入图像的通道,所以同时将像素数据转换为浮点数也很简单。
备注:即使 BNNS 允许你指定整数作为数据和权重的数据类型,它在内部也会将其转换为浮点数据,进行计算,然后将结果转换为整数。为了获得最好的速度,你可能想要跳过这个转换步骤,并且总是直接处理浮点数据,即使它们占用了 2 到 4 倍的内存。
临时数据
在 BNNS 和 MPSCNN 中,每个层级都需要处理。你将数据放入一个层级,并从一个层级中获取数据。
深层网络将会有很多层级。我们只关心最后一层的输出,而不关心所有其他层的输出。但是我们仍然需要将这些中间结果存储在某个地方,即使它们只用了一小会儿。
MPSCNN 对此有一个特殊的对象,MPSTemporaryImage。它就像一个 MPSImage,但只能使用一次。写入一次数据,读取一次数据。之后,它的内存将被回收。(如果您熟悉 Metal,它们是使用 Metal 的资源堆来实现的。)
你应该尽可能地使用 MPSTemporaryImage,因为这样可以避免大量的内存分配和释放。
使用 BNNS 的话就得靠自己。你需要自己管理临时数据缓冲区。幸运的是,它非常简单:您可以分配一个或两个大数组,然后在这些层级之间重复使用它们。
多线程
你可能想要在后台线程中构建网络层级。加载学习参数的所有数据可能需要几秒钟的时间。
在后台线程上执行推断也是一个好主意。
使用足够深的神经网络,推断可能需要 0.1 到 0.5 秒之间的时间,这样的延迟对于用户是很明显的。
使用 MPSCNN 创建一个命令队列和一个命令缓冲区,然后通知所有层级编码到命令缓冲区中,最后将工作提交给 GPU。GPU 完成后,会通过回调通知你。
每项工作的编码都可以在后台线程中进行,你不需要做任何事情来进行同步。
备注:在实时情况下(例如,将摄像机的实时视频帧提供给神经网络时),你希望 GPU 保持繁忙状态,并且避免 CPU 和 GPU 相互等待的情况。当 GPU 仍在处理前一帧时,CPU 应该已经编码了下一个视频帧。你需要使用 MPSImage 对象数组,并通过信号量保证对它们的同步访问——但说实话,如果现在的移动设备能够实时地进行深度学习,我会感到非常惊讶。
BNNS 在 CPU 上工作,所以你可以在后台线程中开始工作,然后阻塞,直到 BNNS 完成。
最好让 BNNS 弄清楚如何在可用的 CPU 内核上分割工作,但是有一个配置选项告诉 BNNS 有多少线程可以用来执行计算。(MPSCNN 不需要这个,它将使用尽可能多的 GPU 线程。)
备注:你不应该在多个线程之间共享 MPSCNN 对象或 BNNS 对象。它们可以在单个后台线程中使用,但不能同时在使用多个线程中使用。
速度问题
决定是否使用 BNNS 或 MPSCNN 是基于一个权衡:CPU 数据更快还是 GPU 更快?
并非所有数据都适合 GPU 处理。图像或视频是非常合适的,但像时间序列数据可能不适合。
将数据加载到 GPU 中是需要花费的,因为你需要将其封装到 MTLTexture 对象中。一旦 GPU 完成,读取结果就需要再次从纹理对象中获取。
使用基于 CPU 的 BNNS,便不会有这些开销,但是你也无法利用 GPU 的大规模并行性来进行计算。
在实践中,开发人员可能会尝试两种方法,看看哪一个更快。但是,如上所示,由于 BNNS 和 MPSCNN 具有不同的 API,因此需要编写两次代码。
因为我很好奇,所以我决定分别使用 BNNS 和 MPSCNN 建立一个非常基本的卷积神经网络来测量哪一个更快。
我的神经网络设计大概是这样(点击图片放大):

这种网络设计可以用来分类图像。网络采用 256×256 的 RGB 图像(无 alpha 通道)作为输入,并产生一个具有 100 个 浮点值 的数组。输出会表示出 100 多种可能类别的对象的概率分布。
实际上,神经网络需要有更多的层级才能真正有用。它最后也本该有一个 softmax 层,但是因为 BNNS 没有使用 softmax 函数,所以我把它去掉了。
我实际上并没有训练这个神经网络来学习任何有用的东西,而是用合理的随机值进行初始化。这是一个没有用的神经网络。然而,它确实允许我们比较在 BNNS 和 MPSCNN 中建立相同的神经网络所需要的内容,以及每个网络运行有多快。
如果你想一起实践,这是 GitHub 上的代码。在 Xcode 中打开这个项目,并在至少有一个 A8 处理器的 iOS 10 兼容设备上运行它(它不能在模拟器上运行)。
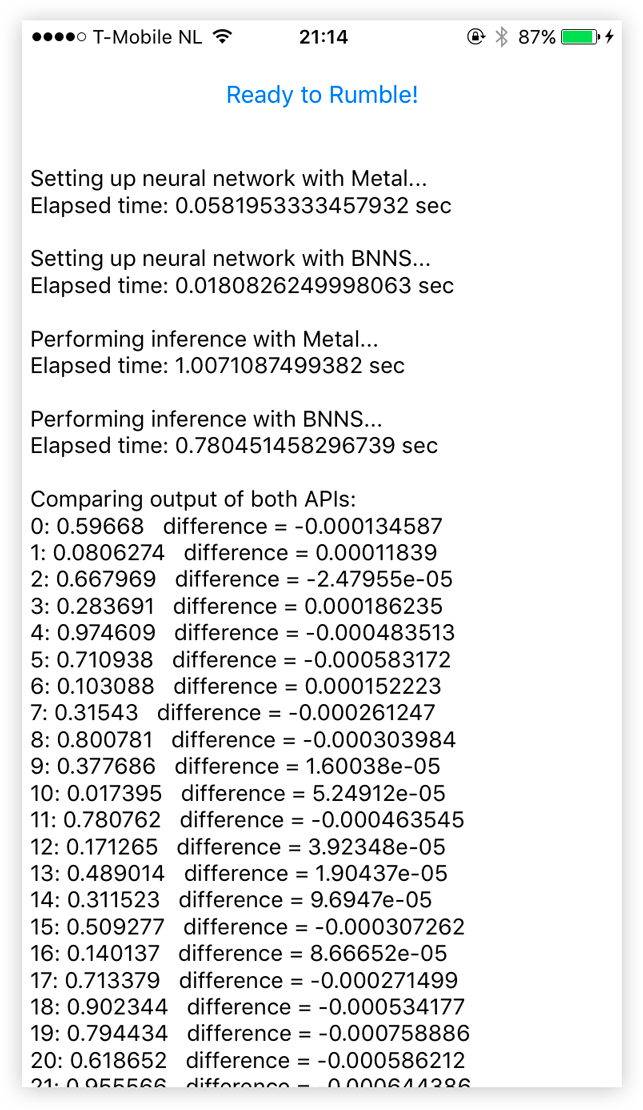
点击按钮后,App 冻结几秒钟,同时在每个神经网络上执行 100 个独立的推断。该 App 显示了创建网络需要多长时间(并不是很有趣),以及需要多长时间才能完成 100 次重复的推断。
该 App 还打印出每个网络计算的结果。由于网络并没有进行训练,因此这些数字什么意义都没有,仅仅是用于调试目的。我想确保两个网络实际上计算的事情相同,从而保证测试是公平的。
答案中的小差异是由于浮点四舍五入(由于 Metal 在内部使用的 16 位浮点数,我们只得到 3 位小数的精度),而且也可能是由于每个框架具体执行计算的差异而产生的。但结果足够接近。
App 的工作原理
该 App 创建了具有 2 个卷积层,1 个最大池层,1 个平均池层和 1 个完全连接层的神经网络。然后,它会测量向网络发送 100 次相同图像需要多长时间。
与此有关的主要源文件是 BNNSTest.swift 和 MetalTest.swift。
你猜对了,BNNSTest 类使用 BNNS 功能创建神经网络。以下是创建第一个卷积层所需的一小段代码:
inputImgDesc = BNNSImageStackDescriptor(width: 256, height: 256, channels: 3,
row_stride: 256, image_stride: 256*256,
data_type: dataType, data_scale: 0, data_bias: 0)
conv1imgDesc = BNNSImageStackDescriptor(width: 256, height: 256, channels: 16,
row_stride: 256, image_stride: 256*256,
data_type: dataType, data_scale: 0, data_bias: 0)
let relu = BNNSActivation(function: BNNSActivationFunctionRectifiedLinear,
alpha: 0, beta: 0)
let conv1weightsData = BNNSLayerData(data: conv1weights, data_type: dataType,
data_scale: 0, data_bias: 0, data_table: nil)
let conv1biasData = BNNSLayerData(data: conv1bias, data_type: dataType,
data_scale: 0, data_bias: 0, data_table: nil)
var conv1desc = BNNSConvolutionLayerParameters(x_stride: 1, y_stride: 1,
x_padding: 2, y_padding: 2, k_width: 5, k_height: 5,
in_channels: 3, out_channels: 16,
weights: conv1weightsData, bias: conv1biasData,
activation: relu)
conv1 = BNNSFilterCreateConvolutionLayer(&inputImgDesc, &conv1imgDesc,
&conv1desc, &filterParams)
使用 BNNS,你需要创建大量“描述符”助手来描述你将要使用的数据以及层级的属性和权重。其他层级也会重复此操作。现在你可以明白为什么我之前说这个会很无聊。
MetalTest 类使用 MPSCNN做同样的事情:
conv1imgDesc = MPSImageDescriptor(channelFormat: channelFormat, width: 256,
height: 256, featureChannels: 16)
let relu = MPSCNNNeuronReLU(device: device, a: 0)
let conv1desc = MPSCNNConvolutionDescriptor(kernelWidth: 5, kernelHeight: 5,
inputFeatureChannels: 3, outputFeatureChannels: 16,
neuronFilter: relu)
conv1 = MPSCNNConvolution(device: device, convolutionDescriptor: conv1desc,
kernelWeights: conv1weights, biasTerms: conv1bias, flags: .none)
在这里你也可以创建各种描述符对象,但代码会短一些。
你已经看到如何使用 BNNS 进行推断:你在每个层级调用一次 BNNSFilterApply():
if BNNSFilterApply(conv1, imagePointer, &temp1) != 0 {
print("BNNSFilterApply failed on layer conv1")
}
if BNNSFilterApply(pool1, temp1, &temp2) != 0 {
print("BNNSFilterApply failed on layer pool1")
}
if BNNSFilterApply(conv2, temp2, &temp1) != 0 {
print("BNNSFilterApply failed on layer conv2")
}
if BNNSFilterApply(pool2, temp1, &temp2) != 0 {
print("BNNSFilterApply failed on layer pool2")
}
if BNNSFilterApply(fc3, temp2, &results) != 0 {
print("BNNSFilterApply failed on layer fc3")
}
在这里,imagePointer 指向一个浮点值的 Swift 数组。同样,temp1 和 temp2 是普通的 Swift 浮点值数组。我们不断重复使用这些数组来存储中间结果。网络的最终输出会写入 [Float] 类型的 results 中。一旦网络完成计算,我们可以立即读取这个数组的结果,并在我们 App 的其他地方使用它们。
使用 MPSCNN 的过程是非常相似的:
let commandBuffer = commandQueue.makeCommandBuffer()
let conv1img = MPSTemporaryImage(commandBuffer: commandBuffer,
imageDescriptor: conv1imgDesc)
conv1.encode(commandBuffer: commandBuffer, sourceImage: inputImage,
destinationImage: conv1img)
let pool1img = MPSTemporaryImage(commandBuffer: commandBuffer,
imageDescriptor: pool1imgDesc)
pool1.encode(commandBuffer: commandBuffer, sourceImage: conv1img,
destinationImage: pool1img)
. . .
fc3.encode(commandBuffer: commandBuffer, sourceImage: pool2img,
destinationImage: outputImage)
commandBuffer.commit()
你创建一个 MPSTemporaryImage 对象来保存当前层级的结果,然后通知层级对其自身使用 encode() 并添加到 Metal 的命令缓冲区。这些 MPSTemporaryImage 对象跟我们在 BNNS 代码中使用的 temp1 和 temp2 的是等价的。MPSCNN 在后台管理自己的存储。
inputImage 和 outputImage 分别是网络的输入和输出,因此保存在持久化的 MPSImage 对象中。
请注意,除非你在命令缓冲区上调用 commit(),否则 GPU 将不会执行任何操作。使用 BNNS,每次调用 BNNSFilterApply() 便会立即开始处理。但是 MPSCNN 中的 layer.encode(...) 只是创建了 GPU 命令,不会马上执行它们。在调用 commit() 之后,GPU 才开始处理数据,而 CPU 可以自由地处理更多东西。
我们真正想要的是神经网络的输出是一个浮点值的数组。BNNS 已经可以处理普通的 Swift 数组,所以在此我们不需要做任何特别的事情。但是对于 MPSCNN,我们需要将输出的 MPSImage 对象的纹理转换成我们可以在 Swift 中使用的东西。在 App 的 MPSImage + Floats.swift 文件中包含一些辅助代码。
备注:如果你使用 BNNS 的 16 位浮点数(你很可能会这样做),那么在某些时候你需要转换回 32 位浮点数。在演示的 App 中,这是在最后一个层级之前做的,而不是之后,因为完全连接层无法处理 16 位浮点数。
测试指标
我想对 BNNS 和 MPSCNN 中创建的完全相同的神经网络的运行时间进行公平的比较。
我没有测试将输入数据转换为正确格式所需的时间。如果输入的数据是图像,并且使用 MPSCNN,你可以将其加载到纹理中,然后就不用管了。但是 BNNS 不行:你需要首先在内存中重新排列图像数据,这可能会非常费时。
然而,这实际上取决于你使用的是什么神经网络,这就是为什么我不想测量它。但是在我们的速度测试中,它确实给 BNNS 带来了轻微的优势,因为对于 BNNS 来说,获得正确形式的输入数据比较慢。
对于输出数据,我测量了将其转换回 Swift 数组所需的时间。在这里,MPSCNN 比较慢,而 BNNS 根本没有成本(如果使用 32 位浮点数的话)。所以这也有利于 BNNS。
然而,我认为在这种情况下的测量中包含转换是公平的,因为转换网络输出是你几乎总要做的事情。这是将 GPU 用于通用计算工作的一个缺点,因此降低了使用 GPU 所带来的性能收益。
对于一个公平的测试,我想在 MPSCNN 和 BNNS 中使用 16 位浮点数。MPSCNN 在内部总是将权重存储为 float16 类型,所以为了保持公正,我们也应该让 BNNS 使用 16 位浮点数。缺点是 Swift 没有“半浮点”类型,所以我们即使在使用 BNNS 时,总是需要用“真实的” 32 位浮点数来回转换。
备注:在 ViewController.swift 文件中有几个选项可以让你改变所测试的东西。特别是,它允许你更改学习参数的数据类型以及层级用来用于执行计算的数据类型。还有一个选项可以增大网络,这会增加所需的计算的数量,因为最初的网络很小,不一定代表真实的深度学习架构。
测试结果
你准备好了吗?
对于基本的 5 层卷积网络,在我的 iPhone 6s 上,使用 16 位浮点数,BNNS 比 MPSCNN 快大约 25%。
所以这是CPU的胜利。
然而,如果我们在每一层中通过提供更多的处理通道(改变 App 中的乘数值)来使网络更庞大,MPSCNN 将轻松超越 BNNS。
当使用 32 位浮点数时,MPSCNN 也比 BNNS 更快。(可能是因为 MPSCNN 在内部总是使用 16 位浮点数,但 BNNS 现在有两倍的工作量。)
作为一个全面的指导方针,如果发送到网络的推断需要做超过3亿次的浮点运算,那么最好切换到 MPSCNN。
我以下面的方式来到这个数字:
Number of flops per layer = 2 × kernelWidth × kernelHeight ×
inputChannels × outputChannels ×
outputWidth × outputHeight
然后我为每一层添加了触发器,并试验了网络的大小,来验证 MPSCNN 变得比 BNNS 更快的临界点。
警告:这是一个超级不科学的实验,我的计算可能会失败。但是,如果你为深层网络做了一个后台计算,并且发现它需要 1 Gflops(每秒10亿次的浮点运算数)或更多,那么很明显 BNNS 就不行了。
但请注意,这取决于许多因素:
-
设备类型。我只在iPhone 6s上测试过。在较慢的 iPhone 6 或较快的 iPhone 7 上,性能可能会有所不同。
-
你的数据。正如我所指出的,MPSCNN 可以轻松地将图像加载到纹理中,但对于 BNNS ,你需要首先完全重新排列像素数据。你需要执行的预处理会对性能产生影响。
-
同样,为了在 Swift 中使用而对网络输出的数据进行的任何转换,都可能会减慢处理过程。
-
内存带宽。在我的 VGGNet 实现中,学习参数占用大约 260 MB 的 RAM。对于每个推断,神经网络不仅需要做大量的计算,还需要访问数百万个存储单元。随时都可能遇到带宽的瓶颈。
我试图尽可能公平地进行测试,但是由于这两个框架中的错误和其他怪异行为,使得过程并不完美。
例如,BNNS 全连接层不能接受 16 位浮点数,所以我必须先将数据转换回 32 位浮点数。由于完全连接层执行了大量的计算,如果支持这些半精度浮点数,BNNS 可能会更快。MPSCNN 的一些层级也有自己的怪异之处(详见源代码)。
备注:我没有测试批处理。这两个 API 都可以一次处理多个输入图像。这只会增加一次性向网络发送的数据量。然而,GPU 可能在这方面有优势,因为批处理可能会更好地使用 GPU 带宽。
总结
所以应该使用哪个 API?看情况™。
这两个 API 功能都有限,而且仍然有一些不足之处。对于较小的网络,BNNS 速度较快,但较大的网络速度较慢。BNNS 的功能也较少,你必须自己编写更多的代码。总的来说,BNNS API 比 MPSCNN 更丑陋一点,可能是因为它是一个 C API 被导入到 Swift 中。
但是,BNNS 与 MPSCNN 相比有一个优势:它也能运行在 macOS 上。
提示:使用16位浮点数。尽管 16 位浮点数不是 Swift 的本地类型,但它们能使 BNNS 执行得更高效,即使这意味着您必须将常规数组转换为 16 位浮点数,然后再返回。
就个人而言,我可能会坚持 MPSCNN 。它更加灵活,你可以将它与 Metal Performance Shaders 的快速矩阵乘法程序和自己的计算内核结合使用。
最重要的是你的 App 运行得有多快,以及推断的效果如何。
如果你的项目紧急,需要快点,请使用 MPSCNN。但是如果你能腾出时间,那最好用这两种 API 来分别实现你的神经网络,并且看看你能将哪个调整到最佳效率。