Scrapy 架构介绍
14 Dec 2017
前言
目前来看,Python 最适合练手的项目就是爬虫了。Requests、BeautifulSoup 之类的单拿出来都有点像玩具,于是想试下 Scrapy。这篇先介绍下 Scrapy 的架构,主要内容来自官方文档 Architecture overview,展示了 Scrapy 的架构以及它的组件间如何交互。
数据流
下图主要展示了 Scrapy 的架构,以及组件间的数据(红色箭头)流动。下面将对这些组件以及数据流进行简要介绍。
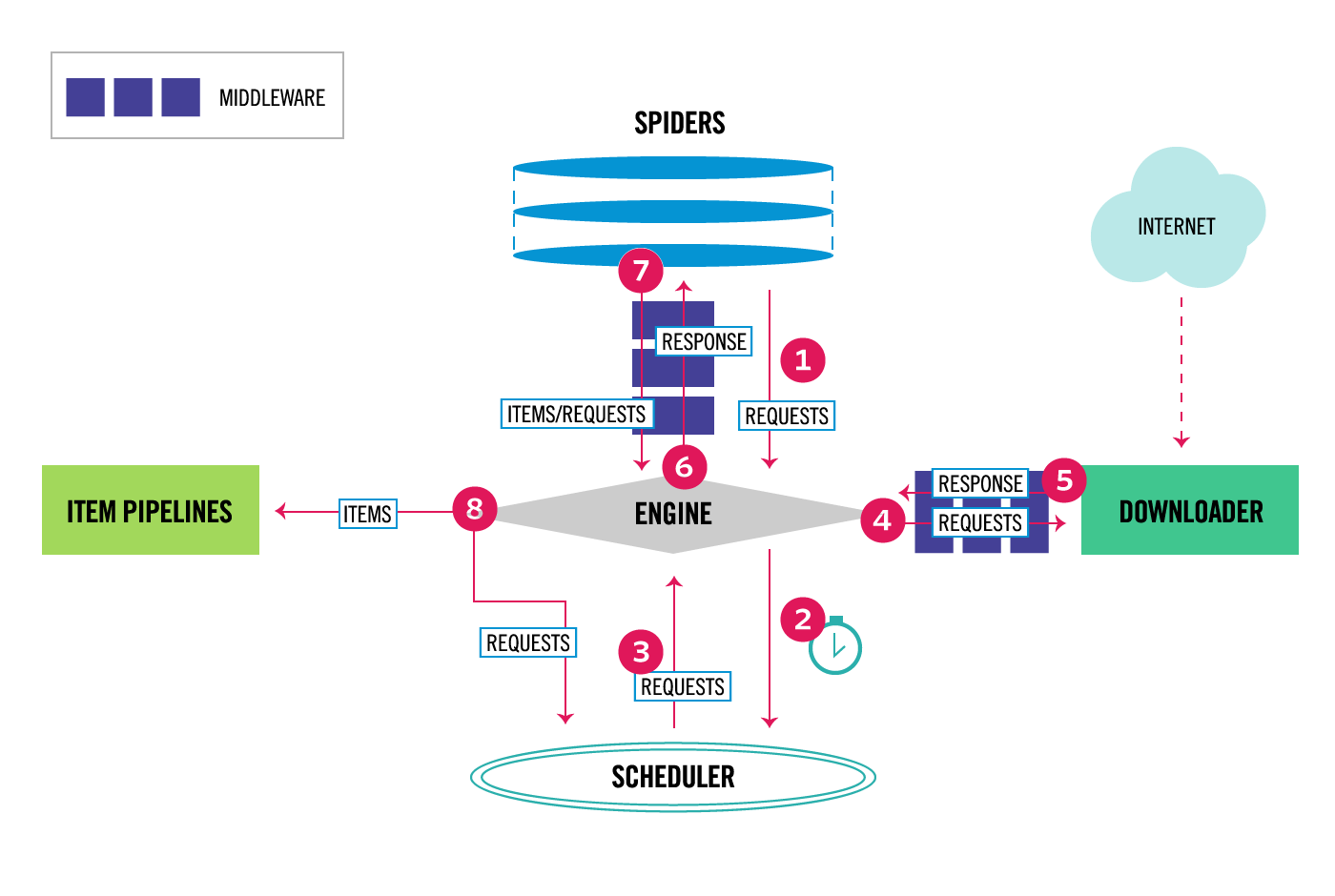
在 Scrapy 中,数据流由执行引擎控制,主要步骤有:
- Engine 从 Spider 获取需要抓取的初始 Requests。
- Engine 把 Requests 传递给 Scheduler,进行统一调度,同时获取下一个要抓取的 Requests。
- Scheduler 将接下来要抓取的 Requests 返回给 Engine
- Engine 将这些 Requests 通过 Downloader Middlewares(
process_request()) 传递给 Downloader。 - 一旦页面下载完成,Downloader 会生成一个 Response(包含页面内容)并通过 Downloader Middlewares(
process_response())将其发送到 Engine。 - Engine 收到来自 Downloader 的 Response ,再通过 Spider Middleware(
process_spider_input())将其发送给 Spider 进行解析。 - Spider 解析 Response,并通过 Spider Middleware(
process_spider_output())将解析的内容和后续的 Requests 返回给 Engine。 - Engine 将处理过的内容发送给 Item Pipelines,然后将后续的 Requests 发送给 Scheduler 进行调度,并获取下一个要抓取的 Requests。
- 重复步骤 1,直到处理完 Scheduler 中所有的抓去请求。
其中,我觉得 2 和 8 中 Engine 与 Scheduler 的交互过程应该这样理解,Engine 把要抓取的 Requests 都交给 Scheduler,进行类似队列的管理,同时 Scheduler 会不断地将下一次要抓取的 Requests 传递给 Engine。也就是说,Scheduler 负责维护 Requests 的列表,决定抓取的先后顺序。
组件介绍
Scrapy Engine
Engine 负责控制系统所有组件之间的数据流,并在发生某些操作时触发相应的事件。具体可以查看 数据流 的的内容。
Scheduler
Scheduler 接收来自 Engine 的抓取请求,并将它们排入队列,以便在 Engine 请求时将其提供给 Engine。
Downloader
Downloader 负责获取网页并将其返回给 Engine,然后 Engine 将其发送给 Spiders。
Spiders
Spiders 是我们编写的自定义类,用于解析响应并从中提取所需要的内容或接下来要抓取的请求。更多内容请查看 Spiders。
Item Pipeline
Item Pipeline 负责处理 Spiders 解析后的内容。例如,数据清洗、验证、持久化(存储到数据库)等。更多内容请查看 Item Pipeline。
Downloader middlewares
Downloader middlewares 处于 Engine 和 Downloader 之间。通过 Downloader middlewares,Engine 将 requests 传递给 Downloader,同时 Downloader 将下载的 responses 传回给 Engine。
以下的操作都请使用 Downloader middlewares:
-
将请求发送到 Downloader 之前对其进行处理(也就是 Scrapy 向网站发送请求之前);
-
将响应发送到 spider 之前对响应进行处理;
-
发送新的 Request,而不是将接收到的响应传递给 spider;
-
不请求网络的情况下向 spider 返回响应;
-
丢弃某些请求。
更多内容请查看 Downloader middlewares。
Spider middlewares
Spider middlewares 位于 Engine 和 Spiders 之间。负责处理 Spiders 的输入(响应)和输出(解析出内容和请求)。
以下工作可以使用 Spider middlewares:
-
修改 Spider 输出的内容 —— 比如说更改/添加/删除请求或内容;
-
修改起始的网络请求;
-
处理 Spider 的异常;
-
根据响应内容调用 errback,而不是返回网络请求。
更多内容请查看 Spider middlewares。
Event-driven networking
Scrapy 是用 Twisted 编写的,这是一个流行的事件驱动的 Python 网络框架。因此,它使用非阻塞(异步)代码来实现并发。
有关异步编程和 Twisted 的更多信息,请参阅这些链接: